Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThis blog was inspired by a talk that Laurent Doguin, a developer advocate over at Couchbase, and I gave at Couchbase Connect last year. Merci Laurent!
This is a demo of the Spring Data Couchbase integration. From the project page, Spring Data Couchbase is:
The Spring Data Couchbase project provides integration with the Couchbase Server database. Key functional areas of Spring Data Couchbase are a POJO centric model for interacting with Couchbase Buckets and easily writing a Repository style data access layer.
Couchbase is a distributed data-store that enjoys true horizontal scaling. I like to think of it as a mix of Redis and MongoDB: you work with documents that are accessed through their keys. There are numerous client APIs for all languages. If you're using Couchbase for your backend and using the JVM, you'll love Spring Data Couchbase. The bullets on the project home page best enumerate its many features:
@Configuration classes or an XML namespace for the Couchbase driver.CouchbaseTemplate helper class that increases productivity performing common Couchbase operations. Includes integrated object mapping between documents and POJOs.@Cacheable support to cache any objects you need for high performance access.You will need to have Couchbase installed if you don't already (naturally). Michael Nitschinger (@daschl, also lead of the Spring Data Couchbase project), blogged about how to get a simple 4-node Vagrant cluster up and running here. I've reproduced his example here in the vagrant directory. To use it, you'll need to install Virtual Box and Vagrant, of course, but then simply run vagrant up in the vagrant directory. To get the most up-to-date version of this configuration script, I went to Michael's GitHub vagrants project and found that, beyond this example, there are numerous other Vagrant scripts available. I have a submodule in this code's project directory that points to that, but be sure to consult that for the latest-and-greatest. To get everything running on my machine, I chose the Ubuntu 12 installation of Couchbase 3.0.2. You can change how many nodes are started by configuring the VAGRANT_NODES environment variable before startup:
VAGRANT_NODES=2 vagrant up
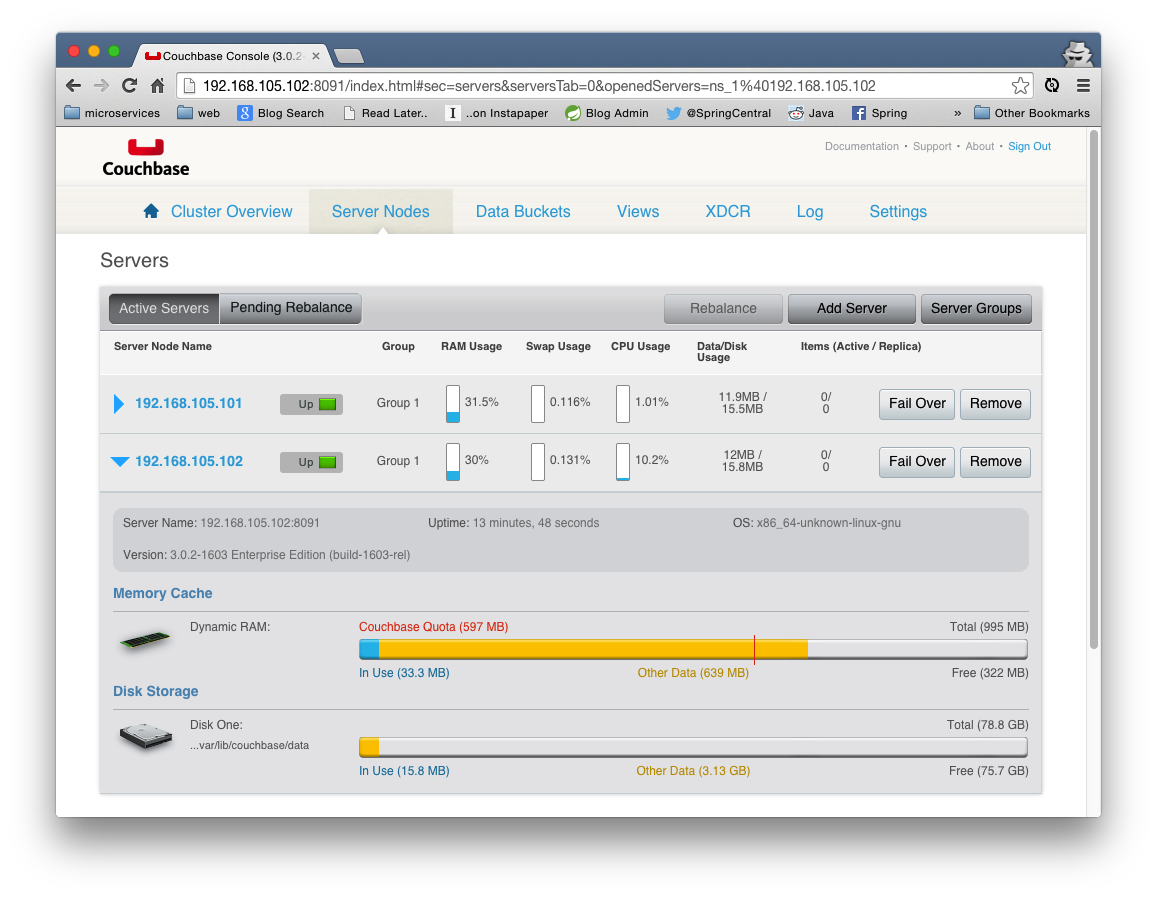
You'll need to administer and configure Couchbase on initial setup. Point your browser to the right IP for each node. The rules for determining that IP are well described in the README. The admin interface, in my case, was available at 192.168.105.101:8091 and 192.168.105.102:8091. For more on this process, I recommend that you follow the guidelines here for the details.
Here's how I did it. I hit the admin interface on the first node and created a new cluster. I used admin for the username and password for the password. On all subsequent management pages, I simply joined the existing cluster by pointing the nodes to 192.168.105.101 and using the aforementioned admin credential. Once you've joined all nodes, look for the Rebalance button in the Server Nodes panel and trigger a cluster rebalance.
If you are done with your Vagrant cluster, you can use the vagrant halt command to shut it down cleanly. Very handy is also vagrant suspend, which will save the state of the nodes instead of shutting them down completely.
If you want to administer the Couchbase cluster from the command line there is the handy couchbase-cli. You can simply use the vagrant ssh command to get into each of the nodes (by their node-names: node1, node2, etc..). Once there, you can run cluster configuration commands. For example the server-list command will enumerate cluster nodes.
/opt/couchbase/bin/couchbase-cli server-list -c 192.168.56.101 -u admin -p password
It's easy to trigger a rebalance using:
/opt/couchbase/bin/couchbase-cli rebalance -c 192.168.56.101 -u admin -p password
Couchbase lends itself to use in the cloud. It's horizontally scalable (like Gemfire or Cassandra) in that there's no single point of failure. It does not employ a master-slave or active/passive system. There are a few ways to get it up and running where your applications are running. If you're running a Cloud Foundry installation, then you can install the the Cumulogic Service Broker which then lets your Cloud Foundry installation talk to the Cumulogic platform which itself can manage Couchbase instances. Service brokers are the bit of integration code that teach Cloud Foundry how to provision, destroy and generally interact with a managed service, like Couchbase, in this case.
Let's look at a simple example that reads data (in this case from the Facebook Places API using Spring Social Facebook's FacebookTemplate API) and then loads it into the Couchbase server.
You'll also need a Facebook access token. The easiest way to do this is to go to the Facebook Developer Portal and create a new application and then get an application ID and an application secret. Take these two values and concatenate them with a pike character (|). Thus, you'll have something of the form: appID|appSecret. The sample application uses Spring's Environment mechanism to resolve the facebook.accessToken key. You can provide a value for it in the src/main/resources/application.properties file or using any of the other supported Spring Boot property resolution mechanisms. You could even provide the value as a -D argument: -Dfacebook.accessToken=...|...

Data in Couchbase is stored in buckets. It's logically the same as a database in a SQL RDBMS. It is typically replicated across nodes and has its own configuration. We'll be using the default bucket, but it's a snap to create more buckets.
Let's look at the basic configuration required to use Spring Data Couchbase (in this case, in terms of a Spring Boot application):
@SpringBootApplication
@EnableScheduling
@EnableCaching
public class Application {
@EnableCouchbaseRepositories
@Configuration
static class CouchbaseConfiguration extends AbstractCouchbaseConfiguration {
@Value("${couchbase.cluster.bucket}")
private String bucketName;
@Value("${couchbase.cluster.password}")
private String password;
@Value("${couchbase.cluster.ip}")
private String ip;
@Override
protected List<String> bootstrapHosts() {
return Arrays.asList(this.ip);
}
@Override
protected String getBucketName() {
return this.bucketName;
}
@Override
protected String getBucketPassword() {
return this.password;
}
}
// more beans
}
Spring Data provides the notion of repositories - objects that handle typical data-access logic and provide convention-based queries. They can be used to map POJOs to data in the backing data store.
Our example simply stores the information on businesses it reads from Facebook's Places API. To acheive this we've created a simple Place entity that Spring Data Couchbase repositories will know how to persist:
@Document(expiry = 0)
class Place {
@Id
private String id;
@Field
private Location location;
@Field
@NotNull
private String name;
@Field
private String affilitation, category, description, about;
@Field
private Date insertionDate;
// .. getters, constructors, toString, etc
}
The Place entity references another entity, Location, which is basically the same.
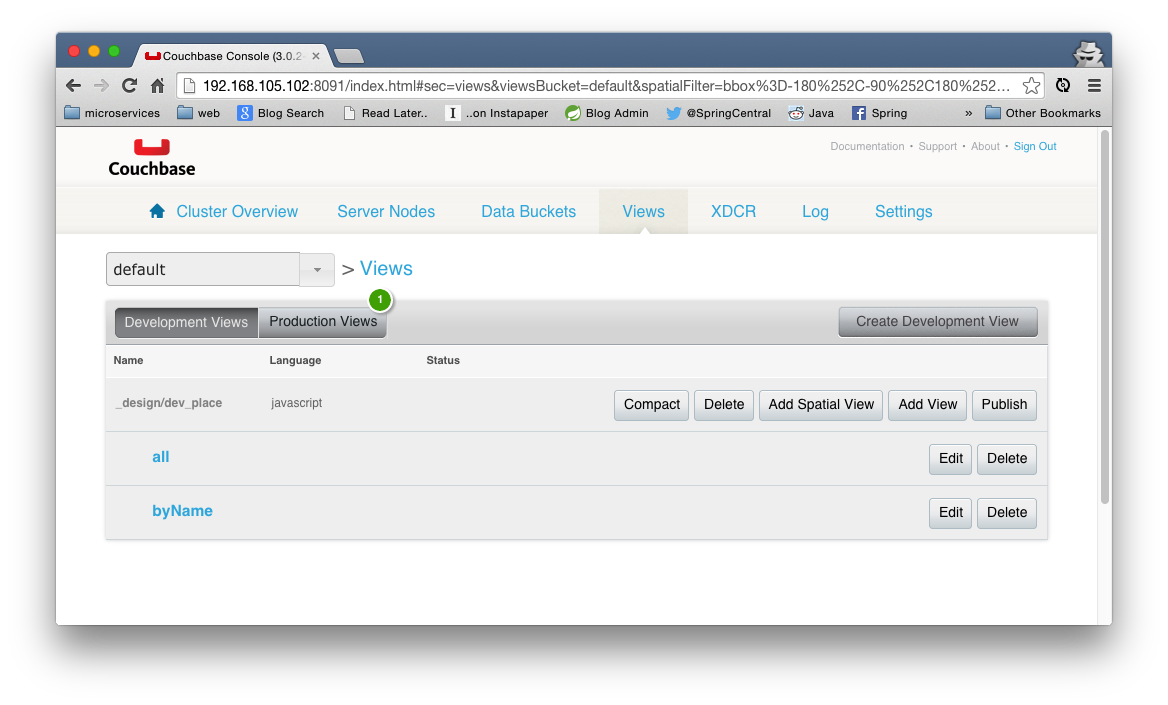
In the case of Spring Data Couchbase, repository finder methods map to views - queries written in JavaScript - in a Couchbase server. You'll need to setup views on the Couchbase servers. Go to any Couchbase server's admin console and visit the Views screen, then click Create Development View and name it place, as our entity will be demo.Place (the development view name is adapted from the entity's class name by default).
We'll create two views, the generic all, which is required for any Spring Data Couchbase POJO, and the byName view, which will be used to drive the repository's findByName finder method. This mapping is by convention, though you can override which view is employed with the @View annotation on the finder method's declaration.
First, all:

Now, byName:

When you're done, be sure to Publish each view!
Now you can use Spring Data repositories as you'd expect. The only thing that's a bit different about these repositories is that we're declaring a Spring Data Couchbase Query type for the argument to the findByName finder method, not a String. Using the @Query is straightforward:
Query query = new Query();
query.setKey("Philz Coffee");
Collection<Place> places = placeRepository.findByName(query);
places.forEach(System.out::println);
We've only covered some of the basics here. Spring Data Couchbase supports the Java bean validation API, and can be configured to honor validation constraints on its entities. Spring Data Couchbase also provides lower-level access to the CouchbaseClient API, if you want it. Spring Data Couchbase also implements the Spring CacheManager abstraction - you can use @Cacheable and friends with data on service methods and it'll be transparently persisted to Couchbase for you.
The code for this example is in my Github repository, co-developed with my pal Laurent Doguin (@ldoguin) over at Couchbase.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all